
Behind the Scenes: K8s
An algorithmic approach to Kubernetes Architecture and Communication Patterns


As a beginner, it always used to bug me, the complications and existence of this nuisance of a thing they call Kubernetes. Gradually, as I gain more and more knowledge, this mess of a thing makes more sense to me. I'm surely not an expert on K8s but against that, I believe no one is, we all are learning. I believe the first step to gaining a grip on K8s is understanding its architecture and hence, here we are, trying to make some sense out of it.
Below I discuss the core components of the giant CNCF project and how it eases my life, behind the scenes.
To start with, let's first make a clear view of the two main components which talk to each other via API calls: CONTROL PLANE & DATA PLANE.
The control plane's components are contained inside the MASTER NODE, whereas the rest of it, the data plane part, which is often replicated, is under the WORKER NODES. Therefore, as a matter of fact, Kubernetes is often defined with the concept of master node architecture. We will take the same approach.
Two types of nodes? WHY?!
Of course from the first look, the master node controls and orders the worker node around. But there is more to it. The concept we are trying to hit here is the mindset behind such an architectural choice. Let's take a brief look at it.
Security and access control:
In my opinion, among the few other well-reasoned factors that play a role in such architectural choices, this is the most important one.
By having a particular set of control-oriented nodes, controlling the other worker nodes, not only provides specific securable entry points but also helps in vulnerability localisation and efficient operations. It isolates the factors where a probable vulnerability can take place and offers more control over the cluster. It provides for better logical isolation.
I'd love to elaborate further upon this interesting topic some other time so look forward to it ;)
Better fault tolerance:
Having multiple nodes working on some stuff concurrently provides a better uptime experience. This takes care of the case where, say, one master node is down, we can have multiple master nodes(more than one generally) running which are taking care of multiple worker nodes, shifting their responsibility as the system requires.
This ensures that even if failures occur, critical cluster management operations are up and running.
Efficiency and scalability:
Having nodes that have logical isolation among themselves provides for what we engineers term as separation of concern. This separation not only provides better scalability but also better resource management and distribution. Separating the execution of the two planes into master and worker, resource allocation and scaling up services become way more neat and straightforward.
Summing up, the control plane focuses on managing and orchestrating the cluster, while worker nodes are responsible for executing application workloads. This logical separation allows for better scalability, fault tolerance and security.
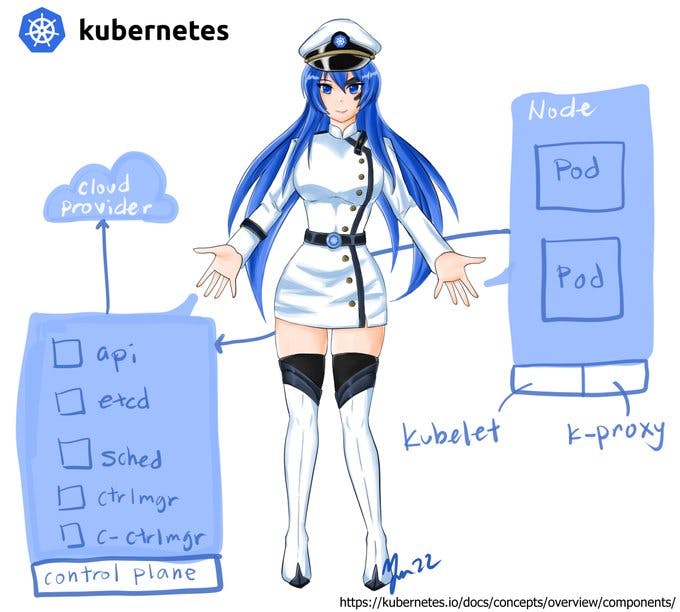
Above is an image of K8s-chan, the orchestrator of Container Dolls and OS-tans, drop her a hello! :3
Since we are now clear with the reasons for opting for such a complicated architecture, let's take a step forward and make things easier just like K8s-chan does ^_^
Kubernetes, HOW?!
Here is a humble diagram of what we are going to discuss:-
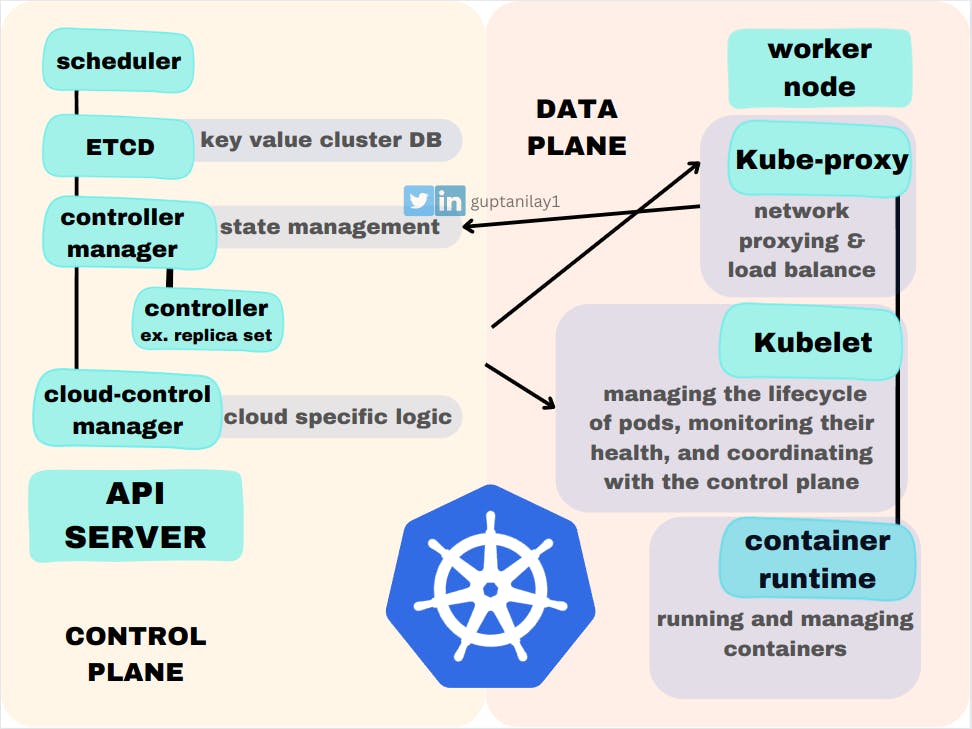
As the diagram states, both the planes themselves are further divided into components with their specific individuality.
Let us take a practical case scenario and follow the flow that is triggered when a command like kubectl apply -f <filename.yaml> is given to the CLI.
API server:
The
kubectlclient communicates with the Kubernetes API Server. It sends a request to apply the desired changes specified in the YAML file.The API server parses the YAML file and extracts resource definitions
A request query is sent to ETCD to verify that the desired state specified in the YAML file does not match with the current state stored in etcd. ETCD is a key value pair-based database used to store the info related to the cluster. Therefore, that process determines if a change needs to be made, if yes, then we proceed to the next steps.
If, upon verification, updates in resource or state are required, they are updated in the ETCD.
Now since there is a change in the ETCD, the controller manager which always looks out for such updates, detects a difference in the current state and the desired state.
This now enables the controller manager to assign the specific controller/s pertaining to which the differences matter. For example, in some cases it might trigger the
replica set controllerwhich is responsible to maintain a specific number of pods.Scheduling: If the applied resources include pods that need to be scheduled, the Scheduler selects suitable nodes for the pods based on resource availability and constraints. Following this, the target pods are notified of the scheduling.
Worker Node/ Data Plane
This notification is received by the KUBELET running on the worker nodes.
[before this point, everything was happening under the control plane contained inside the master node]
Kubelet then pulls required images, sets up the pod's network and storage and starts the container by triggering the container runtime.
The kubelet interacts with the container runtime (e.g., Docker or containerd) to manage the lifecycle of the containers. It starts the containers with the specified configurations and monitors their health.
kube-proxy: kube-proxy is responsible for managing network communication within the cluster. It sets up and maintains network rules to enable network connectivity between pods and services.
Feedback to the User: The Kubernetes API Server sends a response back to the
kubectlclient, providing feedback about the execution of thekubectl applycommand. The user receives the response in the CLI, indicating the success or failure of the resource creation or update.
There you go, all boiled down, the crust, the real working, implimentations, all pilled into just a set of bullet points. I can't imagone a better way to explain such components and makes sense at the same time without using such algorithmic approach.
Hope that helped you in having a better grip of understanding this nuisance of a thing they call Kuberbernetes :)